
-
26.04.2010 11:02:42
Evaluating the NoSQL-System mongoDB for a data driven project
A short test of mongoDB and the NoRM mapper
from: cpom | Comments: 0 -
So, why mongoDB ?!
Friends and coworkes told me to use CouchDB, if I want a real document based DBMS: CouchDB is cool and Google uses it and its fun and has so many new features and its easy… But I never heard any hard technical fact that could me bring to use it. And I don’t want to be part of a Movement.
I work as software developer and that’s one of the reasons why I want facts and not buzz words. When I make a decision, regarding the use of any software, I am often very conservative because customers want it this way. And from my experience, it’s in general a good advice, not to be fashion driven in software development.

Official logo - mongoDB is for "humongous DB"So here are my reasons why I took mongoDB and not Apache CouchDB for my test:
-
mongoDB is written in C++, so it is a compromise between speed, portability and extensibility. It should , in theory, run with little effort on any system with a C++ compiler.
-
A DB system should not depend on and run on a VM (in the meaning of a runtime system like java vm or erlang vm) of any kind. mongoDB is a set of native binaries.
-
mongoDB has a lot of drivers for major languages. Major languages means in this case statically typed: Java, C++, C# etc. I need access from fat clients , not only from a web application written in a dynamic language. I don’t want to write code that accesses raw JSON stuff (error prone).
-
I need speed in both inserting and reading the data. Great scaling capabilities are a “nice to have” as well. As CouchDB, mongoDB claims to have it.
- mongoDB has a OR-Mapper called NoRM, which is in early stages but quiet usable. That is one of the big points: I want an OR Mapper. Mainly for testability and clean, reusable code. It means later in the process: stable and maintainable software.
Installs and runs in No Time - I am impressed !
If you go to mongodb.org, you can download a package for your favourite OS. Windows, Linux, MacOS X and Solaris binaries are available in 32bit and 64bit flavour. I decided to download the Linux 64bit and the Windows 64bit packages. Then I rolled out a new VM with CentOS 5.4 64bit for linux tests.
The first installation stage is simply unpacking the compressed archive, creating a directory where the database files reside and starting the DB. And it runs out of the box, both Windows and Linux with that simply commandline:
mongod --dbpath mydatafiledir -port myport
That is a big plus, no whining, no complaining about a required, but sadly missed strange libray xyz, that nobody nows. It simply runs. Downloaded, extracted and running in 5 min - that’s great.
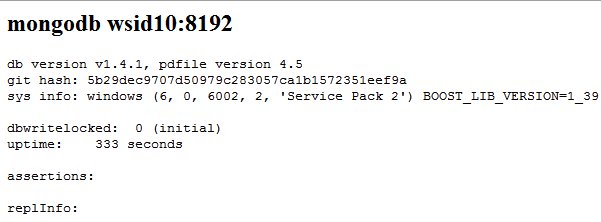 The webinterface
The webinterface
After the db system is up and running you have access to a spartanic non interactive web interface, which provides you some information about db itself and your system.
Using the command line client
MongoDB comes , like many other database systems, with a command line client. If you ever used such a thing, you will feel familiar with it in seconds. Like all other mongoDB binaries, it has a help system, which is easy to understand and to use. You can call it for example with mongo.exe --help or if you are already connected to the db at the mongoDB shell prompt with: help.
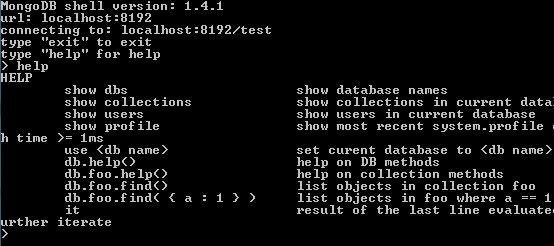 The mongoDB shell
The mongoDB shell
I would recommend, before you write any line of code in your program, try creating, updating and deleting some stuff in the database with the command line client. That helps a lot to understand the concept of this db.
What was very interesting to me, is mongoDBs view of a data table as a collection of objects bound to a key. Every data row is one entry in this collection. A relation is seen as another collection in the database, just like a table in a relational database which is referenced. If you ever used hibernate (or nhibernate or any ORM tool) you know this concept, let us say: hibernate bags.
Preparing the OR Mapper
As mentioned, I want to use NoRM as my programming interface to mongoDB. You can download the source code of NoRM here. A project file for VS2008 and a project file for VS 2010 are included in the archive. I was able to compile it with MSBuild and xbuild from mono 2.6.3 on linux. It compiled cleanly out of the box.
Create your first program
For a first application I create a simple POCO in my project. This plain old C# Object is my DAO and represents a table, or speaking in mongoDB terms: a collection, just like in other OR-Tools. To use it later, it needs at least one property of type ObjectID. The type ObjectID is located in the Norm- Namespace. To iterate properly trough a collection received from the database, it must have the Namespace Norm.Collections too. The name of this property must be ID; otherwise it is assumed the collection is read only.
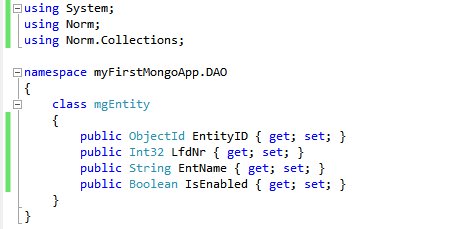
The first entityIn the Main-Method I created a one liner for the connection to the database system. For a connection to localhost on the standard port(which is 27017) I have only to provide the data base name. If it not exist, it will be created .

Create a connection to the DBAt next I created a new MongoCollection typed with mgEntity. You can map it to a table name of your choice if you want to; otherwise it’s named like your DAO. And again: if it does not exist it will be created. Then I wrote a loop for inserting plenty mgEntities. Inside the loop the properties of the object are filled and after that the entity will be saved to db.
The first run took around 25 seconds on a quadcore system with 4 GB of RAM. 100.000 mgEntities were inserted. In the second run 1.000.000 mgEntities were inserted in around 65 sec, in the third run: 2.000.000 in 2 minutes.
The next step was to do a full table scan (myFirstTable.Find()) and to Iterate through the collection and delete in every step a single entity. This went OK as long as the number of entities are not greater than 500.000. Beyond 500.000 I run always into a
First impression
I am satisfied with, from what I have seen in this short test. The DB is easy to setup and to run; the different command line options are documented and clear. The database system itself scales well. The NoRM Mapper is OK, but has some bugs. It took me less the 30 minutes from installation to a first program. Now it is time to start some real world tests with objects that have more properties. And with more than a single collection in the db, but that’s all in part two. From what I have seen so far, makes me think: mongoDB is a nice, easy to use tool.
Kommentar hinzufügen | nach oben
-
mongoDB is written in C++, so it is a compromise between speed, portability and extensibility. It should , in theory, run with little effort on any system with a C++ compiler.
- Comments are disabled
Follow me:
Neueste Artikel:
- Team Foundation Service Preview TFS in the Cloud von: cpom
- Ein erster Eindruck von Visual Studio 11 Express von: cpom
- Ein erster Eindruck von TFS 11 Express von: cpom
- Disabling IPv6 in Windows 7 or Vista von: cpom
- Die Wiederbelebung von: cpom
Kommentare augeschaltet